Ensemble methods(multiple classifier systems)
Ensemble refers to using many to form one, similar to how one would gather information from many sources and aggregate their responses to come up with a wiser decision. Ensemble methods in Machine Learning use multiple learning algorithms to obtain better predictive performance than could be obtained from any of the constituent learning algorithms alone.
Ensemble methods can be divided into averaging methods and boosting methods. Averaging methods are based on averaging the predictions of several estimators while boosting methods have base estimators that are built sequentially and are to reduce the bias of the combined estimator. The commonly used classes of the two methods are forests of randomized trees, bagging, stacking, and gradient tree boosting.
Bagging involves building a predictor on many random subsets of the same dataset and averaging the predictions. It thus reduces the variance of the base estimator. On the other hand, stacking involves fitting many different model types on the same data and using another model to learn how to best combine the predictions. Boosting involves adding ensemble members sequentially that correct the predictions made by prior models and output a weighted average of the predictions.
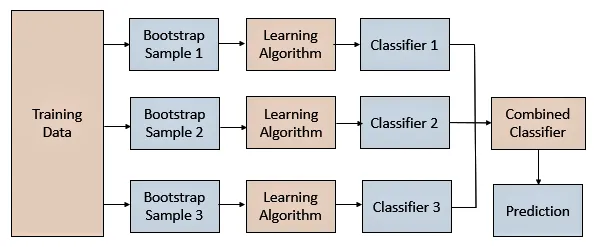
Ensemble methods have three main building blocks as in the image above. This includes data selection which can also be sampling, then training the member models and finally combining the models to make a prediction. The member models would have lower accuracy but when combined, the final prediction is of higher accuracy. This is because the individual members have a generalized prediction of the subset datasets and thus help in solving underfitting and overfitting errors.
The errors are commonly known as bias and variance. Bias is the assumption that a model makes in its prediction. It is simply the difference in the predicted value against the actual value. Variance on the other hand is the changes in the model when using different portions of the training datasets, the variability in the model prediction.
Among issues solved by ensemble methods; are confidence estimation, feature selection, addressing missing features, incremental learning from sequential data, data fusion of heterogeneous data types, learning non-stationary environments and addressing imbalanced data problems, though it was originally meant to reduce variance.
References
- Géron, A. Hands-on Machine learning with Scikit-Learn, Keras, and TensorFlow
- Ensemble Machine learning, 2012
- Ensemble learning algorithms
- Ensemble learning in Python
- Ensemble methods
- Random Forest Classifier


Ensemble Methods in Machine learning